
Zdjęcie: Seej Nguyen
Mam 95-letnią Babcię, która jest maratończykiem audiobooków. Słucha ich na potęgę, ale... półki z gotowymi audioprodukcjami zaczęły się kurczyć. Jako że nuda to stan, którego senior powinien unikać, pomyślałam: A gdyby tak zrobić prezent, którego nie da się kupić?
Wykorzystam model Text-to-Speech (TTS) z funkcją klonowania głosu. Model dostaje mój głos jako "próbkę DNA", a potem czyta teksty, generując audiobooki... moim głosem! Oto krótka historia, jak przekształciłam pliki EPUB w osobistego lektora dla Babci.
Backend: Python i skromne 2 GB RAM-u
Zaczęłam od podstaw, czyli Pythona (a jakże!). Skrypt do obróbki EPUB-ów stworzyłam od zera na potrzeby tego projektu – on tylko ciął i robił wstępną obwódkę. Zero LLM'a, czysta algorytmika: otworzyć, pociąć, podać w pętli. Magia zaczynała się w modelu TTS. Gwiazda projektu: Coqui TTS XTTS v2 z Hugging Face. Multilingualny (świetnie ogarnia polski). Voice cloning capable (wystarczy próbka). Wymaga skromnych ~2 GB RAM. Ale i tak pamiętajcie, żeby zamknąć zbędne aplikacje!
Bitwa o intonację, czyli 200 vs 2000 znaków
Na początku, podeszłam do tematu zero-jedynkowo: chciałam ciąć tekst na 200 znaków i wrzucać do modelu. Efekt? Przerażające, nienaturalne pauzy. Wyglądało to tak, jakby lektor co dwa zdania brał głęboki wdech i zaczynał od nowa. Fatalnie.
Po researchu wydłużyłam bufor do 2000 znaków. Ale to nie wszystko. Trzeba ciąć mądrze. Tekst najpierw jest dzielony po akapitach, potem po zdaniach, na końcu po słowach. W ten sposób cięcie zawsze wypada w naturalnym miejscu, a nie w środku frazy. Intonacja nagle stała się płynna jak Promise JavaScript :) (albo prawie).
Crossfade i Soft Warning: Mądrość XTTS v2
Mimo poprawy, problem słyszalnej ciszy między generowanymi akapitami nadal irytował. Rozwiązanie numer jeden? Crossfade (przenikanie dźwięku). Zamiast brutalnego odcięcia, płynnie łączymy koniec jednego fragmentu z początkiem następnego, nakładając je na siebie. Zero widocznych przerw, płynne przejście. XTTS v2, którego używałam, ma już wbudowany streaming i mechanizmy inteligentnego dzielenia długich próbek!
Jak widzicie na screenie, co jakiś czas pojawiał się komunikat, że przekraczam zalecaną długość 200 znaków. To jest soft warning, nie twardy błąd! Model automatycznie dzielił sobie tekst, a potem sprytnie go sklejał. Dzięki temu, mimo tego ostrzeżenia, tekst był bardzo płynny i nie było tego irytującego odcięcia co 200 znaków. Jeśli będziecie próbowali to powtórzyć – wiedzcie, że ten warning to tylko sugestia, a nie wyrok na wasz audiobook!
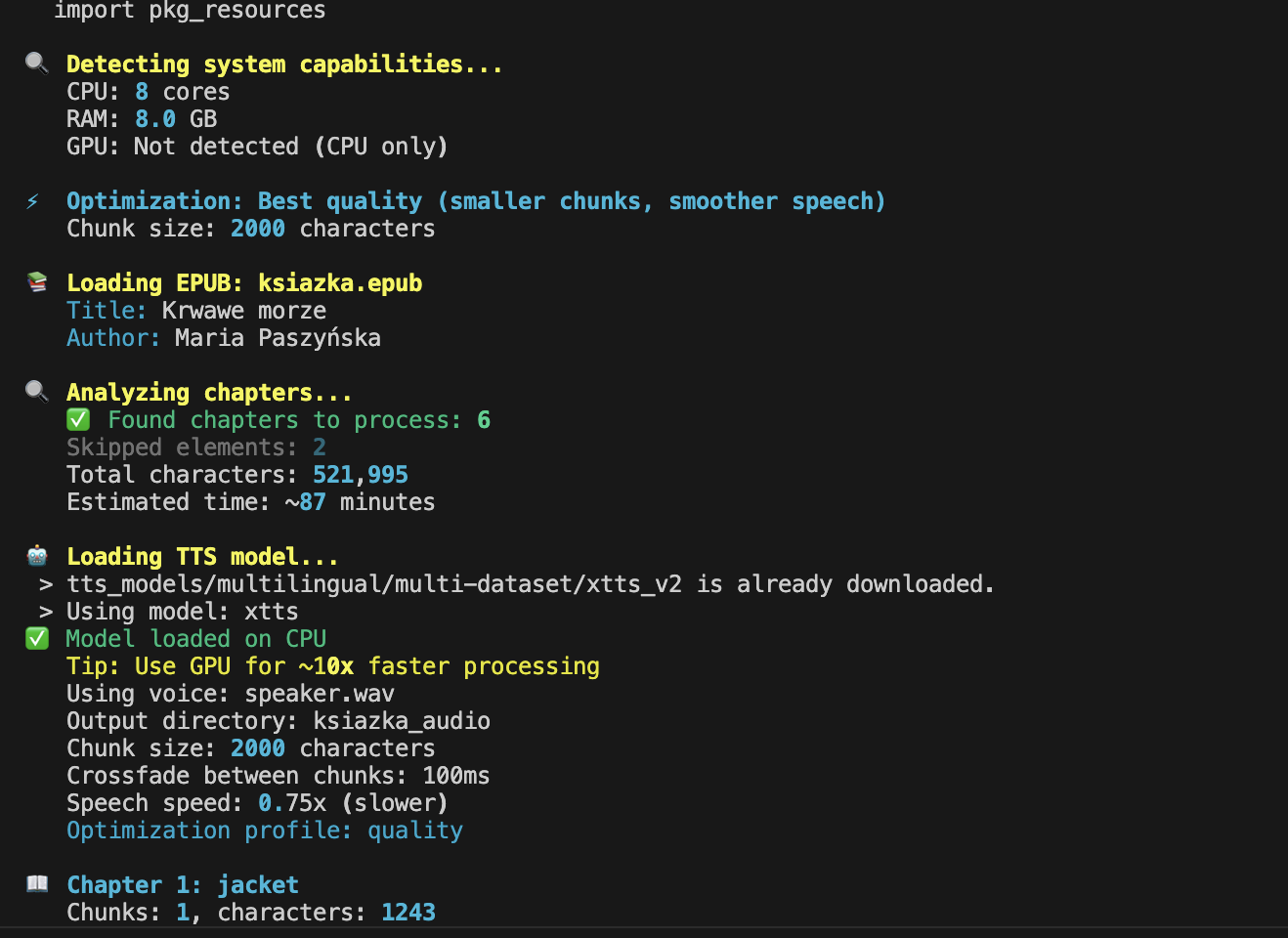
Dodam jeszcze, że podczas kodowania próbowałam dynamicznie szacować, jak długo w czasie zajmuje generowanie książki i pokazywało mi około 87 minut. Ostatecznie okazało się, że to było około dwunastu godzin, więc tutaj jest jeszcze na pewno pole do poprawy (i w kwestii szacowania jak i optymalizacji).
Optymalizacja
Model na początku generował też czytanie okładki, recenzji, wstępów i innych cyfrowych dodatków. To wszystko, co jest look & feel w książce, jest absolutnie niepotrzebne. Wyrzuciłam tę "makulaturę", zostawiłam tylko autora, tytuł i ewentualnie tytuły rozdziałów.
Dodałam też próbę optymalizacji sposobu działania modelu – gdy skrypt wykrywał, że działa na mocnym komputerze z GPU, automatycznie optymalizował ustawienia modelu. Poniżej screen z jednej z prób:
Final Feature: Regulacja Prędkości Słów
Na sam koniec, mały detal, który z punktu słyszenia Babci okazał się kluczowy: prędkość mowy. Domyślne tempo generowania było dla niej zbyt dynamiczne. Dorzuciłam więc prostą flagę do skryptu, która celowo spowalniała generowany tekst. Książka trwała dłużej, ale była o niebo bardziej zrozumiała. A przecież o to chodziło.
Co dalej
Cały ten stack jest oczywiście open source! Zachęcam: jeśli znacie podstawy Pythona, śmiało pobierajcie, odpalajcie i testujcie. Jak to w świecie open source bywa – każda kontrybucja jest mile widziana!
Możliwe, że wokół tego narodzi się społeczność, która zamieni ten projekt w gotową apkę. Ale to już, jak to mówią, future me problem.
Ja na pewno będę rozwijać ten projekt bo widzę, że jest jeszcze pole do poprawy w samej obróbce tekstu, np daty są czytane w nienaturalny sposób. A ponadto Babcia zaczyna testować audiobooki „live" więc pewnie jeszcze niejeden błąd się znajdzie.
Poniżej możecie wysłuchać próbki książki, którą wygenerowałam. To fragment z „Krwawego Morza" Marii Paszyńskiej, wydawnictwo Książnica, 408 stron (nie oceniajcie zamówienia Babci :)).
Wnioski z eksperymentu
Nawet na moim kilkuletnim MacBooku Air da się to ogarnąć. Open-source'owe modele są potężne i dostępne za darmo. Wystarczy trochę Pythona, lokalny asystent kodujący i voilà! Cud zdziałany.
Pewnie, że mogłabym po prostu pójść do ElevenLabs i mieć profesjonalnie brzmiący, dopieszczony audiobook. Zrobiliby to szybciej i pewnie idealnie. Ale przecież nie o to w tym wszystkim chodzi! Własny model, generujący książki 95-letniej Babci, uruchomiony na moim sprzęcie, po zmaganiach z crossfade'em i optymalizacją skryptu - to jest czad!
A jeśli chcecie zacząć od solidnych fundamentów, zróbcie to, co ja: mega polecam Wam kurs „Developer o jutra" Tomasza Ducina na DevStyle. Bez wiedzy z jego szkoleń pewnie nadal traktowałabym AI jak autopilota, którego włączam, gdy chcę coś zakodować. To zadanie domowe od Tomka (własny model Text-to-Speech) było moją bazą, aby pójść o krok dalej i zrobić Babci pełnoprawne audiobooki. Polecam!



